|
Description: Existing volumetric capture systems require many
cameras and lengthy post processing.
We introduce the first system that can capture a
completely clothed human body (including the back)
using a single RGB
webcam and in real time. Our deep-learning-based
approach enables new possibilities for low-cost and
consumer-accessible immersive teleportation.
|
|
Overview
We present the first approach to volumetric performance capture and novel-view rendering at real-time speed from monocular video, eliminating the need for expensive multi-view systems or cumbersome pre-acquisition of a personalized template model. Our system reconstructs a fully textured 3D human from each frame by leveraging Pixel-Aligned Implicit Function (PIFu). While PIFu achieves high-resolution reconstruction in a memory-efficient manner, its computationally expensive inference prevents us from deploying such a system for real-time applications. To this end, we propose a novel hierarchical surface localization algorithm and a direct rendering method without explicitly extracting surface meshes. By culling unnecessary regions for evaluation in a coarse-to-fine manner, we successfully accelerate the reconstruction by two orders of magnitude from the baseline without compromising the quality. Furthermore, we introduce an Online Hard Example Mining (OHEM) technique that effectively suppresses failure modes due to the rare occurrence of challenging examples. We adaptively update the sampling probability of the training data based on the current reconstruction accuracy, which effectively alleviates reconstruction artifacts. Our experiments and evaluations demonstrate the robustness of our system to various challenging angles, illuminations, poses, and clothing styles. We also show that our approach compares favorably with the state-of-the-art monocular performance capture. Our proposed approach removes the need for multi-view studio settings and enables a consumer-accessible solution for volumetric capture.
|
|
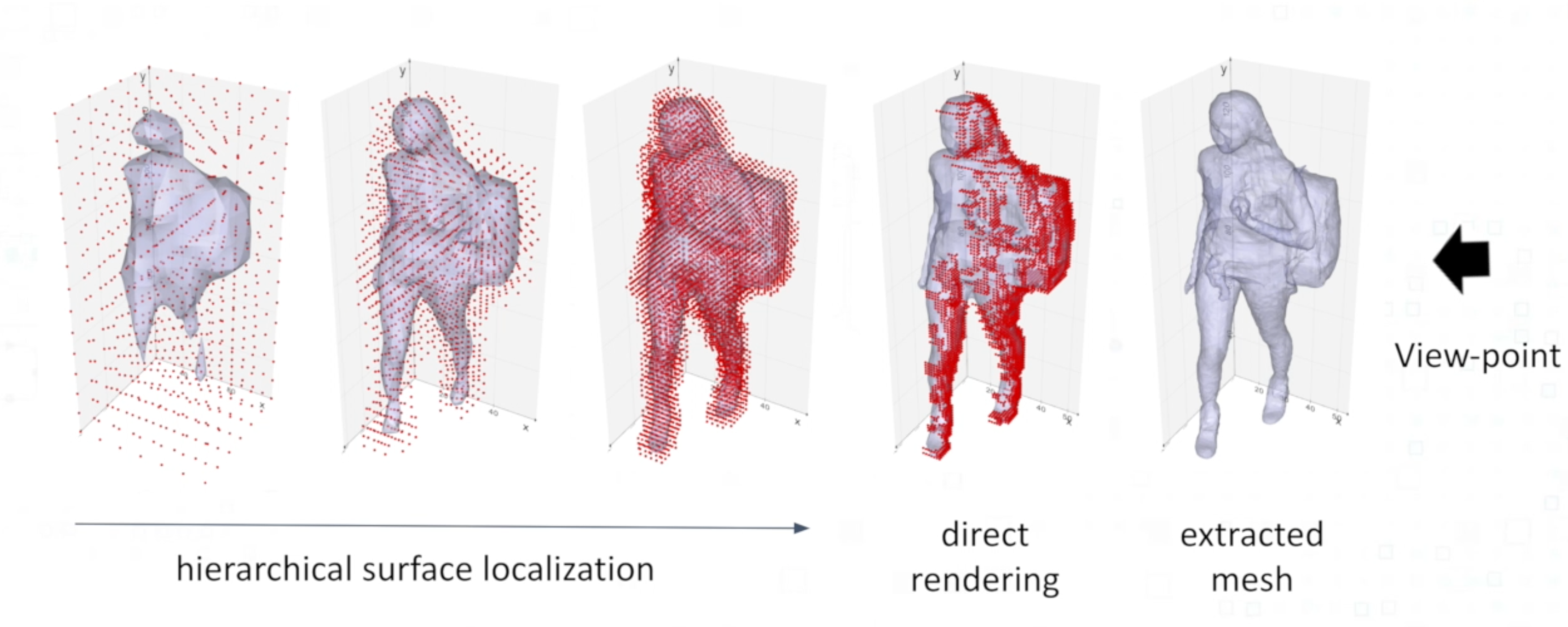
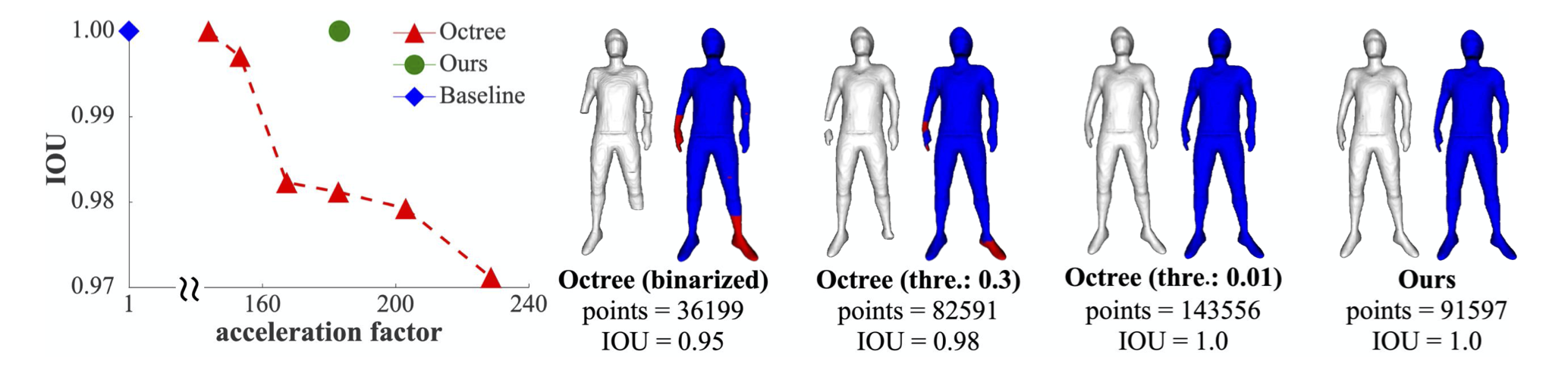
We propose a novel hierarchical surface localization algorithm and a direct rendering method that progressively queries 3D locations in a coarse-to-fine manner and to extract surface from implicit occupancy fields with a minimum number of points to be evaluate. By culling unnecessary regions for evaluation we successfully accelerate the reconstruction by nearly 200 times without compromising the quality.
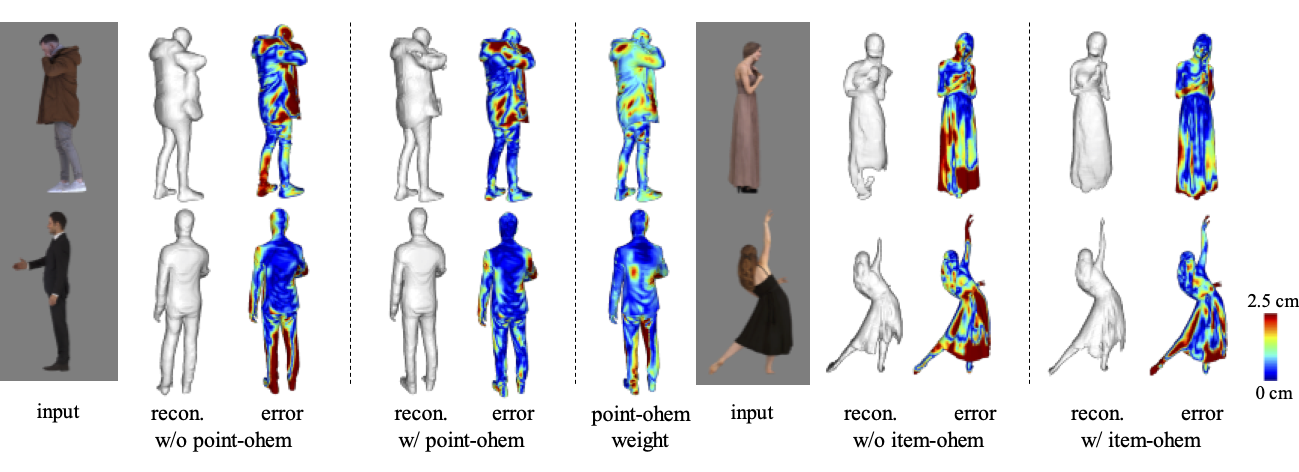
We introduce an Online Hard Example Mining (OHEM) technique that effectively suppresses failure modes due to the rare occurrence of challenging examples. We adaptively update the sampling probability of the training data based on the current reconstruction accuracy, which effectively alleviates reconstruction artifacts.